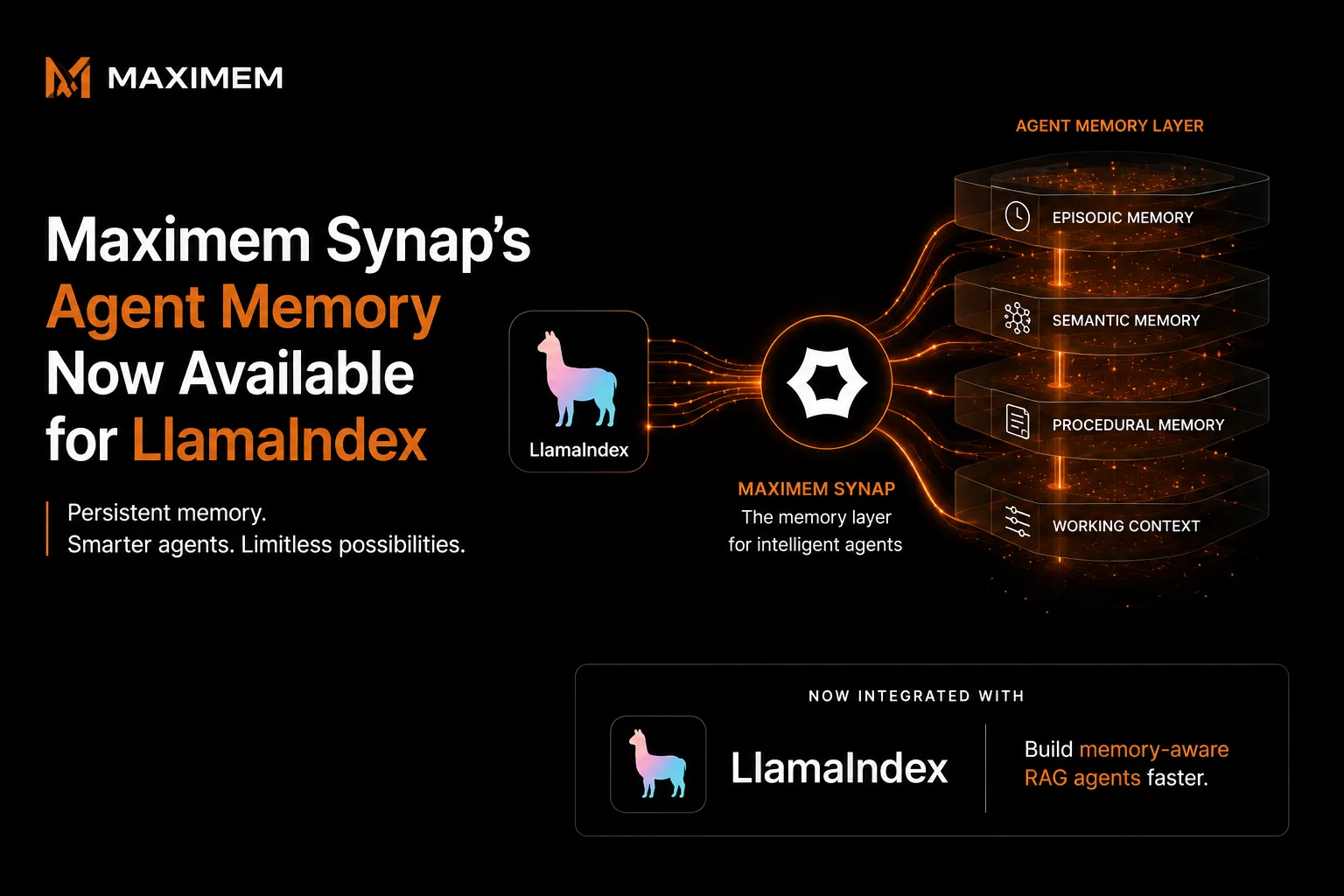
Maximem Synap's Agent Memory Now Available for LlamaIndex
LlamaIndex powers enterprise RAG at scale. Document loaders for every format. Index structures from simple vector stores to hierarchical knowledge graphs. If you are building an agent that reasons over private data, LlamaIndex is where you start.
Today, Maximem Synap extends LlamaIndex with persistent per-user memory. Native memory stores document chunks and query history within a single process. Synap makes that state survive restarts, resolve entities across sessions, and retrieve relevant context without manual wiring.
Where LlamaIndex Excels
LlamaIndex taught developers how to build RAG pipelines that work. Document ingestion with parsers for PDF, Word, HTML, and custom formats. Index structures optimized for different query patterns. Retrieval engines with reranking and hybrid search. Query engines that chain multiple retrievers. If your agent needs to ground answers in private documents, LlamaIndex handles the data plumbing well.
The challenge is what happens when your user comes back tomorrow.
How LlamaIndex Memory Works Today
LlamaIndex ships multiple memory options for chatbots and agents. All store data within a single process lifetime. For a deeper look at how each works,see the LlamaIndex memory documentation.
ChatSummaryBuffer keeps a running summary of the conversation plus recent messages. The summary grows stale as new messages arrive. You trade token efficiency for accuracy loss. Summarization is lossy. Stanford research found that a single summary pass drops accuracy from 66.7% to 57.1%. Each additional pass loses more.
VectorMemoryStore embeds chat messages and retrieves by semantic similarity. Better than simple buffers, but still limited to similarity search. It has no concept of entities. No temporal awareness. It cannot resolve that "John from Acme" and "[email protected]" are the same person.
KnowledgeGraphMemory builds a graph of entities and relationships from conversation history. Promising for relational queries, but the graph is built from scratch each session. Prior graphs do not persist across restarts.
SimpleComposableMemory wraps a chat history buffer with optional retrieval. Works for single-session chat. Does not survive process restarts.
Cross-session persistence, entity resolution, compaction, and per-user scoping across restarts fall outside what these classes were designed to handle. Those are infrastructure problems.
What Synap Adds
Synap is agentic context management. It does not replace LlamaIndex's memory. It extends it with a persistence layer.
We ship three components that plug into LlamaIndex's native interfaces:
SynapChatSource implements ChatSource. Attach it to any chat engine. It captures every turn in the background and ingests it into Synap asynchronously. No code changes to your engine logic. No latency added to your execution. The engine keeps working. The agent starts remembering.
SynapMemory implements BaseMemory. Use it as your memory backend. Per-user, per-conversation scoping. State survives restarts. Prior messages replay on the next session without manual setup.
SynapRetriever implements BaseRetriever. Fetch user-scoped memories alongside document chunks as standard LlamaIndex NodeWithScore objects. Two modes: fast (vector-only, 50 to 100ms) and accurate (graph traversal + reranking, 200 to 500ms).
The integration is a native package. Drop it in, replace the memory backend, and your engine picks up persistent memory without a rewrite.
We built this because RAG agents kept stalling in production. Not from bad retrieval logic. From missing context that lived in a different session last Tuesday. Production testing hit 90.2% on LongMemEval. Fast mode retrieves in under 100ms.
For why context management is infrastructure and not a feature, read What Is Agentic Context Management?. For build-versus-buy numbers, see The Real Cost of DIY Agent Memory.
What Synap Adds to LlamaIndex
Persistence
LlamaIndex Native. In-process only. State clears on restart. With Synap. Per-user memory survives across sessions and restarts.
Entity Resolution
LlamaIndex Native. Raw identifiers. No linking across sessions. With Synap. "John" and "[email protected]" resolve to one canonical entity across every
session.
Compaction
LlamaIndex Native. Manual summarization. Lossy. With Synap. Automatic and configurable. Accuracy-preserving compaction that does not drop critical facts.
Retrieval Latency
LlamaIndex Native. Depends on vector store setup. With Synap. 50 to 100ms fast mode. 200 to 500ms accurate mode.
Long-Term Recall
LlamaIndex Native. Not benchmarked for cross-session recall. With Synap. 90.2% on LongMemEval.
Failure Handling
LlamaIndex Native. Retrieval failures crash the chain or return noise. With Synap. Empty result and a logged error. Your engine keeps running.
User Scoping
LlamaIndex Native. Session-scoped only. With Synap. Built-in user_id, conversation_id, customer_id scoping out of the box.
What Production Teams Gain
Cross-session continuity. Your user chats on Monday, returns on Wednesday. SynapMemory replays prior context. SynapRetriever surfaces relevant facts from last week. The agent treats every session as one continuous conversation. Native memory treats every session as a fresh start.
Accuracy that ships. 90.2% on LongMemEval measures whether agents recall facts across long, multi-turn conversations spanning multiple sessions.
Token efficiency. Synap's compaction trims conversation history without dropping critical context. Most teams see 60 to 70% fewer tokens shipped to the LLM per turn. At scale, that is the difference between profit and burn.
Latency that does not block. Fast retrieval: 50 to 100ms. Accurate mode with graph traversal and reranking: 200 to 500ms. Both degrade without crashing. A failure returns empty results and a log line, not a broken engine.
Entity resolution. "John from Acme," "[email protected]," and "user_4829" resolve to one person across every session. Synap handles this at the memory layer so your engine nodes do not have to.
Production resilience. The chat source captures turns in the background without adding latency. The retriever returns empty results on failure instead of crashing. The memory replays prior messages per session. All three components implement standard LlamaIndex interfaces. No wrappers. No adapters.
How to Get Started
Setup
Install the package alongside LlamaIndex:
pip install maximem-synap-llamaindex llama-index llama-index-llms-openai
Configure your API key. Generate one from the Synap Dashboard.
.env
SYNAP_API_KEY=synap_your_key_here
OPENAI_API_KEY=your-openai-api-key
Initialize the SDK once at application startup:
from maximem_synap import MaximemSynapSDK
sdk = MaximemSynapSDK() await sdk.initialize()
See SDK Initialization for the full lifecycle and configuration options.
Basic integration The smallest useful integration plugsSynapChatMemoryinto any LlamaIndex chat engine. Past turns are loaded automatically on each call, and new turns are persisted on the way out:
from llama_index.core.chat_engine import CondensePlusContextChatEngine from synap_llamaindex import SynapChatMemorymemory = SynapChatMemory( sdk=sdk, conversation_id="conv-001", user_id="alice", customer_id="acme", # optional — required for B2B instances )
chat_engine = CondensePlusContextChatEngine.from_defaults( retriever=your_doc_retriever, memory=memory, )
response = await chat_engine.achat("What were my action items from last week?")
SynapChatMemoryloads prior messages onget()and writes new turns back to Synap onput().Failed reads return an empty buffer and log an error; failed writes surface explicitlyso callers know if persistence failed.To make user-specific memoriesretrievableinside the chat engine (alongside or in place of documents), layer inSynapRetrieverbelow.
Memory is Infrastructure
LlamaIndex gave the world a standard for RAG. Real value. The memory layer it ships handles in-session state well. Making that state persist across
sessions, resolve entities, and retrieve intelligently is a different problem.
The teams that ship production RAG agents discover this around month three. They either build memory infrastructure themselves, or they plug in a system
built for the problem.
This is why memory is infrastructure, not a feature.
Start building LlamaIndex agents that remember across sessions → (https://synap.maximem.ai)
Synap pricing is usage-based. You pay for memory operations: storage, retrieval, compaction. No per-seat or per-framework surcharge. Starter plan:
$49/month. Every new account gets $25 in free credits to test before committing. See full pricing at https://synap.maximem.ai/pricing.
Related Posts
- Maximem Synap's Agent Memory Now Available for LlamaIndex
- I Spoke to 500+ Voice AI Builders in India Over 3 Months. Here Is What I Found.
- Maximem Synap's Agent Memory Now Available for Vercel AI SDK


